


前言
在前几天的系列文章中,我们已经深入探讨了 DeepSeek 模型的蒸馏技术、量化策略,以及 7B、32B 和 671B 量化版本模型的部署要点与性能评估,帮助大家在不同的资源条件下选择合适的模型部署方案。
随着企业对 AI 应用探索的深入,DeepSeek 系列的671B 满血版模型凭借强大的超复杂任务推理能力,成为企业提升竞争力的关键。但因其参数量巨大,单卡或单机部署无法发挥全部性能。多机多卡部署结合 ZStack AIOS 平台,是释放其潜力的关键。本文将详细介绍在 AIOS 平台多机多卡部署 671B 满血版模型的实践过程,分析其性能表现,为企业 AI 技术落地提供有力支撑和指导。
本文目录
一、DeepSeek 模型推理性能的理论分析
二、DeepSeek 模型推理性能的优化手段
三、企业级部署与实践:成本与性能的权衡
四、生产应用中的后续优化思路
五、结语
六、展望
一、DeepSeek 模型推理性能的理论分析
对于现在的这些大模型来说,其GPU运行过程可以简化为下面几步:
1、对输入文本进行转换,从汉字或者单词转换成大模型能理解的数字(向量和位置编码);
2、基于模型的参数进行计算,此时需要将模型的参数(以 Qwen2.5-72B 为例就是 145GB 数据)加载到计算单元进行计算;
3、生成回答,本质上是生成候选词和概率分布。

在这个过程中,对于GPU 硬件有两个参数最为重要:
1.矩阵乘法的性能,也就是我们常说的 GPU 的 TFlops;
2.GPU 显存带宽,因为要从显存把模型参数读取过来,这个与显存采用 GDDR 还是 HBM 有关。
对于现代 GPU 来说,后者的“瓶颈效应”往往大于前者,我们可以将一些常见 GPU 的算力和显存带宽列出来:

可以看到以 RTX 4090 为例,以 FP8 来计算每秒可以处理 82TB 的数据,但是显存带宽每秒只可以加载 1TB 的数据。因此在大模型推理时,当“并发量”较小时,往往显存带宽是瓶颈,只有当“并发量足够大”,才会从“显存瓶颈”转换为“算力瓶颈”,这也是为什么很多 671B 模型测试通过增加更大的并发可以带来更大的吞吐的原因。

基于 671B 模型的理论性能估算
对于 DeepSeek V3、R1 来说其总参数是 671B,其神经网络但得益于 MoE 的架构,运行时的激活参数只有 37B,若采用 FP8 表示,每个参数占 1 字节,则单 token 需要读取数据:
37B×1字节=37GB
注意对于 FP16 表示则需要翻倍为 74 GB/ token。
假设 GPU 的内存带宽约为 1979 GB/s,则单卡下不进行并行拆分时,每个字节需要计算时间约为18.7ms /tokens
对应吞吐大约 53.5 tokens/s。
注意:这里的计算基于“极限下”的理论下界,实际中由于重叠计算、缓存命中以及 KV-cache 读取(随着序列增长,其开销也逐步增加)和其他各种一些优化方法或显示情况会有所不同。
这个计算虽然比较粗略,而且没有考虑张量并行所带来的优化(每个 GPU 只需要加载更少的激活参数),但由于张量并行所带来的通信、同步开销而且会导致显存带宽使用率的下降,其数值和我们实际测试 DeepSeek 单用户推理的性能比较接近,除非采用一些激进的优化手段,否则单用户推理性能很难提升到 53.5 tokens/s 以上。
二、DeepSeek 模型推理性能的优化手段
对于大模型推理来说,优化手段有三类:
1、数据层面优化,例如压缩提示词,减少不必要的提示词,但目前我们的性能瓶颈主要不在提示词解码阶段,而且我们的优化目标不是 QPS(每秒完成请求数)而是 TPS(每秒输出 Token 数),因此暂时不考虑;
2、模型层面优化,DeepSeek 在模型层面实现了 MLA、MoE,并且采用了 FP8 训练,这里简单介绍一下:
a.MLA 架构:与传统 MHA 对比,MLA 在保持超强表达能力 的同时大幅减少了 KV-cache 的大小,从而降低内存带宽与显存需求。
b.MoE 架构:通过将 Dense 模型拆分为多个专业化专家,仅激活部分专家(DeepSeek-V3 为 8 个 routed experts + 1 个 shared expert),使得每 token 只需要计算和读取 37B 权重,而不是 671B,从而大幅降低计算与内存访问成本。

c.低精度 FP8 训练与量化:直接采用 FP8 权重使得读写数据量减少一半,同时对 KV-cache 进行量化(DeepSeek-V2 将 KV-cache 压缩至平均 6 bit),在保持精度的同时大幅降低内存占用。
3、系统层面优化,包括提升并行度、使用投机解码、计算的优化等,这里大部分优化手段是比较通用的,但 MTP 用于投机解码是 DeepSeek 模型较为特有的一个优化,这里简单做一点说明
a.MTP 模块:MTP 模块主要在训练中用于增强预测效果,但在推理阶段可通过投机采样方式提高解码阶段的效率,据官方数据,额外预测 token 的准确率在 85%–90%,可带来约 1.8 倍的 TPS 提升。
三、企业级部署与实践
成本与性能的权衡
DeepSeek-V3 论文所给出的部署方案(H800 集群上,每个部署单元需要 352 张 H800)通过高并行充分发挥 GPU 的性能,这样虽然能够达到非常高的吞吐,但成本也同样很高。为了在较低成本下尽可能实现高吞吐,我们可以首先测试了在较少的 GPU 下的性能
1)单台 H200 八卡场景
环境配置

性能表现
在没有开启投机解码时:

我们也尝试了打开 MTP 投机解码,也辅以一些其他优化手段:


通过启用MTP投机解码和其他优化方法后的主要观察结果:
吞吐量与首字时间的关系:在低并发(1-32)情况下,优化后系统能同时提高吞吐量并保持或降低首字时间,实现了双赢。
高并发场景下的权衡:在128并发下,首字延迟和吞吐都不如优化前的数据
总体而言,MTP投机解码优化在保持良好吞吐量的同时,在大多数场景下也能提供较好的首字响应时间,但在非常高并发时存在一定的响应时间增加。这是因为投机解码有一定的计算开销,在大批量并行时可能会抵消投机解码带来的收益。
2)两台 H20 96GB 十六卡场景
因 H200 相对较难获得,我们使用两台 H20 96GB * 8 进行测试,配置网络条件后先以 TP=16 观察不同并发、不同网络延迟的性能表现。
补充说明:TP 指张量并行(Tensor Parallel)
环境配置

服务器内部硬件拓扑示意:

在 ZStack AIOS 平台部署的效果:
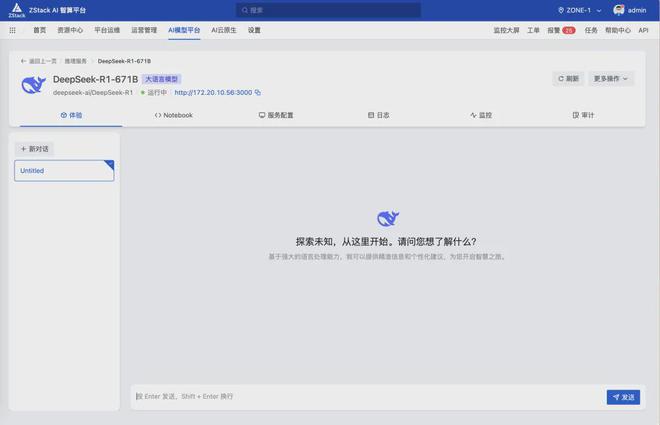
接下来,我们继续通过 ZStack AIOS 平台的服务评测工具测试性能:

TP16 的性能表现

为了验证网络延时对 TP16 部署方案的影响,我们通过 tc 人为地对网络设置了延时,比较不同网络延时下张量并行的吞吐量(TPS):

总结成图表观察:

通过上述的测试,可以发现
从表格和图表可以看出,随着网络延迟从 0.193ms 逐渐增加至 2.193ms,TP16 部署方案下张量并行的吞吐量(TPS)从 18.943 tokens/s 持续下降到 4.85 tokens/s,性能衰减最大达到 74%。说明网络延迟的增加会导致 TP16 吞吐性能显著下降
另外,由于本次是单并发测试,网络延时对 TP16 吞吐量的影响已经很明显。因此在设计和部署 TP16 方案时,应尽量减少网络延时,以优化吞吐量和性能。
四、生产应用中的后续优化思路
尽管通过以上手段已经大幅提升了推理效率,未来在大规模集群环境中还可以尝试一些更加激进的优化策略,可能能够再数倍的提升性能,例如
采用更DP+EP、TP+EP等混合并行技术:
a.原理
DP 能够在大批量输入时通过并行计算来提高整体推理速度,同时不用增加单个设备的负担。EP 则充分利用 MoE 只激活部分专家的特点,降低推理资源消耗、提升速度,二者结合使得大模型推理性能更加提升。

b.案例
就在昨天 Deepseek 官方新开源了 DeepEP ,它是为专家混合 (MoE) 和专家并行 (EP) 量身定制的通信库。它提供了负载均衡和通信策略,解决了传统 DP+EP 方案中的负载不均衡和通信开销大的问题,从而在大规模 MoE 模型训练中实现了更高的计算效率和更好的扩展性。该库还支持低精度运算,包括 FP8
优化冗余专家策略:冗余专家策略除了动态调整单卡上冗余专家的数量外,未来可考虑更智能的全局路由方案,进一步平衡各卡负载。目前的冗余专家策略虽然已经在一定程度上实现了负载均衡,如 DeepSeek 在预填充阶段通过复制高负载专家并冗余部署,每 10 分钟定期调整,还在节点内 GPU 之间重新安排专家。但随着大集群规模的扩大和应用场景的复杂化,更智能的全局路由方案能更好地适应变化,实时优化负载分布。
深化通信和 PD 分离:通信优化针对节点内 NVLink 与跨节点 IB 的分层通信,可尝试采用硬件级通信加速器或网络协处理器,进一步降低延迟。在大集群环境下,节点间通信量巨大,像 Decode 阶段,采用 IB 直接点对点传输和 IBGDA 技术虽已降低延迟,但面对不断增长的推理需求,硬件级的优化手段能从底层提升通信效率。通过引入通信加速器或协处理器,能缓解网络拥堵,保障数据快速传输,满足大集群对低延迟的严苛要求。

拓展多微批次重叠利用:同时处理两个微批次策略,可更充分地隐藏前向与后向通信时的空闲时间,从而进一步逼近理论吞吐极限。在大集群推理中,这一策略效果更为突出。以 DeepSeek 为例,其在 Prefill 阶段就采用了两个计算量相当的 micro-batches,将一个 micro batch 的 Attention 和 MoE 计算与另一个 microbatch 的 Disptach 和 Combine 操作 overlap,有效提高了吞吐量。在 Decode 阶段,也在探索类似方式,将一个 Microbatch 的注意力计算与另一个 microbatch 的 Dispatch + MoE + Combine 操作 Overlap ,未来进一步拓展这种方式,有望挖掘更大的性能潜力。
五、结语
通过上述理论分析与实验,我们验证了大模型在不同并发下的性能瓶颈。通过结合 DeepSeek 模型独有的MLA 与 MoE 架构优势,并利用 FP8 量化和 MTP 模块,可以充分发挥 GPU 硬件的性能。在网络上可以根据不同的网络条件,灵活配置并行策略,以最优化整个系统的吞吐。
未来,还可通过专家并行、数据并行、冗余专家、通信优化和多微批次重叠等策略进一步提高系统性能,为大规模落地应用提供更为坚实的技术保障。
以上便是基于当前理论及 DeepSeek 系列模型部署实践的完整解读与企业实施方案展望。希望本文能为各位工程师和企业决策者在大模型部署过程中提供参考与启发。
六、展望
在 AI 领域,模型迭代日新月异,下一个具有颠覆性的模型或许转瞬即至。因此,企业需建立长效的模型筛选与评估机制,紧跟技术潮流。企业在选择 AI 模型时,应依据业务实际需求,挑选合适参数量的模型和硬件部署方案,实现推理效果与成本的最佳平衡
在后续的文章中,我们将继续探讨:
国产GPU部署策略:如何在国产GPU运行Deepseek模型、推理表现和性能如何。
我们将持续优化和关注 DeepSeek 模型推理的性能和性价比方案,为企业级应用提供更加全面和细致的部署方案,帮助更多行业快速落地大语言模型技术,实现商业价值。


 沪公网安备 31011202014879号
沪公网安备 31011202014879号